For the past 12 months I've been keeping metrics on the types of issues that get reported to the private Apache Software Foundation security alert email address. Here's the summary for Jul 2006-Jun 2007 based on 154 reports:
|
User reports a security vulnerability (this includes things later found not to be vulnerabilities) | 47 (30%) | ||
|
User is confused because they visited a site "powered by Apache" (happens a lot when some phishing or spam points to a site that is taken down and replaced with the default Apache httpd page) | 39 (25%) | ||
|
User asks a general product support question | 38 (25%) | ||
|
User asks a question about old security vulnerabilities | 21 (14%) | ||
|
User reports being compromised, although non-ASF software was at fault (For example through PHP, CGI, other web applications) | 9 (6%) |
That last one is worth restating: in the last 12 months no one who contacted the ASF security team reported a compromise that was found to be caused by ASF software.
The National Vulnerability Database provides a public severity rating for all CVE named vulnerabilities, "Low" "Medium" and "High", which they generate automatically based on the CVSS score their analysts calculate for each issue. I've been interested for some time to see how well those map to the severity ratings that Red Hat give to issues. We use the same ratings and methodology as Microsoft and others use, assigning "Critical" for things that have the ability to be remotely exploited automatically through "Important", "Moderate", to "Low".
Given a thundery Sunday afternoon I took the last 12 months of all possible vulnerabilities affecting Red Hat Enterprise Linux 4 (from 126 advisories across all components) from my metrics page and compared to NVD using their provided XML data files. The result broke down like this:
| Red Hat |
| ||||
| NVD |
|
So that looked okay on the surface; but the diagram above implies that all the issues Red Hat rated as Critical got mapped in NVD to High. But that's not actually the case, and when you look at the breakdown you get this result: (in number of vulnerabilities)
| NVD: High |
|
| NVD: Moderate |
|
| NVD: Low |
|
That shows nearly half of the issues that NVD rated as High actually only affected Red Hat with Moderate or Low severity. Given our policy is to fix the things that are Critical and Important the fastest (and we have a pretty impressive record for fixing critical issues), it's no wonder that recent vulnerability studies that use the NVD mapping when analysing Red Hat vulnerabilities have some significant data errors.
I wasn't actually surprised that there are so many differences: my hypothesis is that many of the errors are due to the nature of how vulnerabilities affect open source software. Take for example the Apache HTTP server. Lots of companies ship Apache in their products, but all ship different versions with different defaults on different operating systems for different architecture compiled with different compilers using different compiler options. Many Apache vulnerabilities over the years have affected different platforms in significantly different ways. We've seen an Apache vulnerability that leads to arbitrary code execution on older FreeBSD, that causes a denial of service on Windows, but that was unexploitable on Linux for example. But it has a single CVE identifier.
So if you're using a version of the Apache web server you got with your Red Hat Enterprise Linux distribution then you need to rely on Red Hat to tell you how the issue affects the version they gave you -- in the same way you rely on them to give you an update to correct the issue.
I did also spot a few instances where the CVSS score for a given vulnerability was not correctly coded. CVSS version 2 was released last week and once NVD is based on the new version I'll redo this analysis and spend more time submitting corrections to any obvious mistakes.
But in summary: for multi-vendor software the severity rating for a given vulnerability may very well be different for each vendors version. This is a level of detail that vulnerability databases such as NVD don't currently capture; so you need to be careful if you are relying on the accuracy of third party severity ratings.
It sometimes seems like me and my team are pushing security updates every day, but actually a default installation of Enterprise Linux 4 AS was vulnerable to only 3 critical security issues in the first two years since release. But to get a picture of the risk you need to do more than count vulnerabilities. My full risk report was published today in Red Hat Magazine and reveals the state of security since the release of Red Hat Enterprise Linux 4 including metrics, key vulnerabilities, and the most common ways users were affected by security issues. It's all about transparency, highlighting the bad along with the good, and rather than just giving statistics and headlines you can game using carefully selected initial conditions we also make all our raw data available too so we can be held accountable.
Red Hat Enterprise Linux 5 was released back in March 2007 so let's take a quick look back over the first three months of security updates to the Server distribution:
- We released updates to ten packages on the day we shipped the product. These is because we freeze packages some months before releasing the product (more information about this policy). Only one of those updates was rated critical, an update to Firefox.
- For the three months following release we shipped 31 more advisories to address 56 vulnerabilities: 3 advisories were rated critical, 8 were important, and the remaining 20 were moderate and low.
- The three critical advisories were:
- Another update to Firefox where a malicious web site could potentially run arbitrary code as the user running Firefox. Given the nature of the flaws, Execshield protections in RHEL5 should make exploiting these issues harder.
- An update to Samba where a remote attacker could cause a heap overflow. In addition to Execshield making this harder to exploit, the impact of any sucessful exploit would be reduced as Samba is constrained by an SELinux targeted policy (enabled by default).
- An update to the Kerberos telnet deamon. A remote attacker who can access the telnet port of a target machine could log in as root without requiring a password. None of the standard protection mechanisms help prevent exploitation of this issue, however the krb5 telnet daemon is not enabled by default in RHEL5 and the default firewall rules block remote access to the telnet port. This flaw did not affect the more common telnet daemon distributed in the telnet-server package.
- Updates to correct all of these critical issues were available via Red Hat Network on the same day as the issues were made public.
As part of our security measurement work since March 2005 we've been tracking how the Red Hat Security Response Team first found out about each vulnerability we fix. This information is interesting as can show us which relationships matter the most, and identify trends in vulnerability disclosure. So for two years to March 2007 we get the following results (in percent):
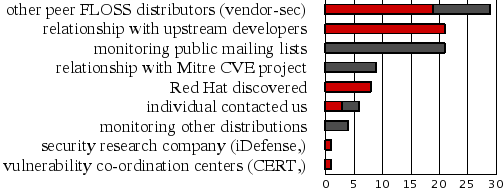
I've separated the bars into two sections; the red sections are where we get notice of a security issue in advance of it being public (where we are told about the issue 'under embargo'). The grey sections are where we are reacting to issues that are already public.
The number of issues through researchers and co-ordination centers seem lower than perhaps expected, this is because in many cases the researcher will tell a group such as vendor-sec rather than each distributor separately, or the upstream project directly.
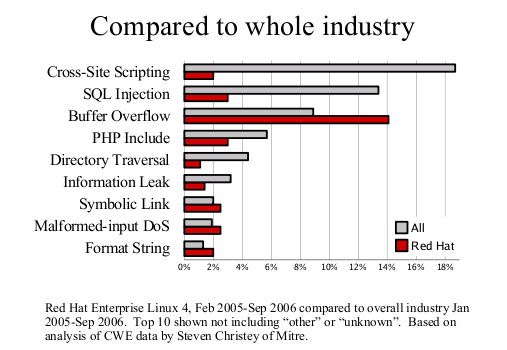
Earlier this month, Steve Christey posted a draft report of the Vulnerability Type Distributions in CVE. The report notices, amongst other things, some differences between open and closed source vendors. I thought it would be more interesting to focus just on one of our released distributions to see if it made a difference to the trends. Steve kindly provided some reports based on a list of CVE names I gave him, and this led to the analysis and these two graphs.

First, the Vulnerability Type Distribution graph. This is not really a big surprise, the most common vulnerabilities we fix are buffer overflows. Technologies such as ExecShield (PIE, support for NX, FORTIFY_SOURCE and so on) were designed specifically to reduce the risk of being able to exploit this flaw type. Secondly, compared to the industry as a whole we fix far less web application flaws such as cross-site scripting or SQL injection. This result is to be expected as most of these are in PHP web applications we don't ship in our distributions.
Our usual security audit for Fedora Core 6 is now available. For 20020101 to 20061023 there are a potential 1758 CVE named vulnerabilities that could have affected FC6 packages. 93% of those are fixed because FC6 includes an upstream version that includes a fix, 1% are still outstanding, and 6% are fixed with a backported patch. Most of those outstanding issues are for low or moderate severity flaws that are not fixed upstream.
The full details broken out by CVE name are available as at GOLD (fixed) or latest status (updated daily)
There's a new Apache HTTP Server security issue out today, an off-by-one bug that affects the Rewrite module, mod_rewrite. We've not had many serious Apache bugs in some time, in fact the last one of note was four years ago, the Chunked Encoding Vulnerability.
This issue is technically interesting as the off-by-one only lets you write one pointer to the space immediately after a stack buffer. So the ability to exploit this issue is totally dependent on the stack layout for a particular compiled version of mod_rewrite. If the compiler used has added padding to the stack immediately after the buffer being overwritten, this issue can not be exploited, and Apache httpd will continue operating normally. Many older (up to a year or so ago) versions of gcc pad stack buffers on most architectures.
The Red Hat Security Response Team analysed Red Hat Enterprise Linux 3 and Red Hat Enterprise Linux 4 binaries for all architectures as shipped by Red Hat and determined that these versions cannot be exploited. We therefore do not plan on providing updates for this issue.
In contrast, our Fedora Core 4 and 5 builds are vulnerable as the compiler version used adds no stack padding. For these builds, the pointer being overwritten overwrites a saved register and, unfortunately, one that has possible security consequences. It's still quite unlikely we'll see a worm appear for this issue that affects Fedora though: for one thing, the vulnerability can only be exploited when mod_rewrite is enabled and a specific style of RewriteRule is used. So it's likely to be different on every vulnerable site (unless someone has some third party product that relies on some vulnerable rewrite rules). Even then, you still need to be able to defeat the Fedora Core randomization to be able to reliably do anything interesting with this flaw.
So, as you can probably tell, I spent a few days this week analysing assembler dumps of our Apache binaries on some architectures. It was more fun than expected; mostly because I used to code full-time in assembler, although that was over 15 years ago.
In the past I've posted timelines of when we found out about issues and dealt with them in Apache; so for those who are interested:
20060721-23:29 Mark Dowd forwards details of issue to security@apache.org 20060722-07:42 Initial response from Apache security team 20060722-08:14 Investigation, testing, and patches created 20060724-19:04 Negotiated release date with reporter 20060725-10:00 Notified NISCC and CERT to give vendors heads up 20060727-17:00 Fixes committed publically 20060727-23:30 Updates released to Apache site 20060828 Public announcement from Apache, McAfee, CERT, NISCCHere is the patch against 2.0, the patch against 1.3 or 2.2 is almost identical.
Remember all those reports which compared the number of security vulnerabilities in Microsoft products against Red Hat? Well researchers have just uncovered proof and an admission that Microsoft silently fix security issues; in one case an advisories states it fixes a single vulnerablity but it actually fixes seven.
Whilst you could perhaps argue that users don't really care if an advisory fixes one critical issue or ten (the fact it contains "at least one" is enough to force them to upgrade), all this time the Microsoft PR engine has been churning out disingenuous articles and doing demonstrations based on vulnerability count comparisons.
In March 2005 we started recording how we first found out about every security issue that we later fixed as part of our bugzilla metadata. The raw data is available. I thought it would be interesting to summarise the findings. Note that we only list the first place we found out about an issue, and for already-public issues this may be arbitrary depending whoever in the security team creates the ticket first.
So from March 2005-March 2006 we had 336 vulnerabilities with source metadata that were fixed in some Red Hat product:
111 (33%) vendor-sec 76 (23%) relationship with upstream project (Apache, Mozilla etc) 46 (14%) public security/kernel mailing list 38 (11%) public daily list of new CVE candidates from Mitre 24 (7%) found by Red Hat internally 18 (5%) an individual (issuetracker, bugzilla, secalert mailing) 15 (4%) from another Linux vendors bugzilla (debian, gentoo etc) 7 (2%) from a security research firm 1 (1%) from a co-ordination centre like CERT/CC or NISCC(Note that researchers may seem lower than expected, this is because in many cases the researcher will tell vendor-sec rather than each entity individually, or in some cases researchers like iDefense sometimes do not give us notice about issue prior to them making them public on some security mailing list)
