It sometimes seems like me and my team are pushing security updates every day, but actually a default installation of Enterprise Linux 4 AS was vulnerable to only 3 critical security issues in the first two years since release. But to get a picture of the risk you need to do more than count vulnerabilities. My full risk report was published today in Red Hat Magazine and reveals the state of security since the release of Red Hat Enterprise Linux 4 including metrics, key vulnerabilities, and the most common ways users were affected by security issues. It's all about transparency, highlighting the bad along with the good, and rather than just giving statistics and headlines you can game using carefully selected initial conditions we also make all our raw data available too so we can be held accountable.
Red Hat Enterprise Linux 5 was released back in March 2007 so let's take a quick look back over the first three months of security updates to the Server distribution:
- We released updates to ten packages on the day we shipped the product. These is because we freeze packages some months before releasing the product (more information about this policy). Only one of those updates was rated critical, an update to Firefox.
- For the three months following release we shipped 31 more advisories to address 56 vulnerabilities: 3 advisories were rated critical, 8 were important, and the remaining 20 were moderate and low.
- The three critical advisories were:
- Another update to Firefox where a malicious web site could potentially run arbitrary code as the user running Firefox. Given the nature of the flaws, Execshield protections in RHEL5 should make exploiting these issues harder.
- An update to Samba where a remote attacker could cause a heap overflow. In addition to Execshield making this harder to exploit, the impact of any sucessful exploit would be reduced as Samba is constrained by an SELinux targeted policy (enabled by default).
- An update to the Kerberos telnet deamon. A remote attacker who can access the telnet port of a target machine could log in as root without requiring a password. None of the standard protection mechanisms help prevent exploitation of this issue, however the krb5 telnet daemon is not enabled by default in RHEL5 and the default firewall rules block remote access to the telnet port. This flaw did not affect the more common telnet daemon distributed in the telnet-server package.
- Updates to correct all of these critical issues were available via Red Hat Network on the same day as the issues were made public.
As part of our security measurement work since March 2005 we've been tracking how the Red Hat Security Response Team first found out about each vulnerability we fix. This information is interesting as can show us which relationships matter the most, and identify trends in vulnerability disclosure. So for two years to March 2007 we get the following results (in percent):
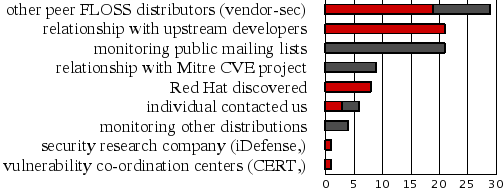
I've separated the bars into two sections; the red sections are where we get notice of a security issue in advance of it being public (where we are told about the issue 'under embargo'). The grey sections are where we are reacting to issues that are already public.
The number of issues through researchers and co-ordination centers seem lower than perhaps expected, this is because in many cases the researcher will tell a group such as vendor-sec rather than each distributor separately, or the upstream project directly.
Red Hat has shipped products with randomization, stack protection, and other security mechanisms turned on by default since 2003. Vista recently shipped with similar protections and I read today an article about how the Microsoft Security Response Team were not treating Vista any differently when rating the severity of security issues. The Red Hat Security Response team use a similar guide for classification and I thought it would be worth clarifying how we handle this very situation.
We rate the impact of individual vulnerabilities on the same four point scale, designed to be an at-a-glance guide to how worried Red Hat is about each security issue. The scale takes into account the potential risk of a flaw based on a technical analysis of the exact flaw and it's type, but not the current threat level. Therefore the rating given to an issue will not change if an exploit or worm is later released for a flaw, or if one is available before release of a fix.
For the purpose of evaluating severities, our protection technologies fall into roughly three categories:
- Security innovations that completely block a particular type of security
flaw. An example of this is Fortify
Source. Given a particular vulnerability we can evaluate if the flaw would
be caught at either compile time or run time and blocked. Because this is
deterministic, we will adjust the security severity of an issue where we can
prove it would not be exploitable.
- Security innovations that should block a particular security flaw from being
remotely exploitable. Examples of this would be support for NX, Randomisation,
and Stack canaries.
Although these technologies can reduce the likelyhood of exploiting certain
types of vulnerabilities, we don't take them into account and don't downgrade
the security severity.
- Security innovations that try to contain an exploit for a vulnerability. I'm thinking here of SELinux. An attacker who can exploit a flaw in any of the remotely accessible daemons protected by a default SELinux policy will find themselves tightly constrained by that policy. We do not take SELinux into account when setting the security severity.
I've not been keeping a list of vulnerabilities that are deterministically blocked, but I have a couple of examples I recall where we did alter the severity:
- In October 2005 a buffer overflow flaw
was found in the authentication
code of wget. On Fedora Core 4 this flaw was not exploitable it was
caught by Fortify Source.
- In August 2004, a double-free flaw in MIT Kerberos KDC was announced. For users of Red Hat Enterprise Linux 4 users we were able to downgrade the severity of this flaw from critical as glibc hardening prevented this double-free flaws being exploited. The flaw was rated important as it could still lead to a remote denial of service (KDC crash)
Enterprise Linux 5 has been consuming much of my time over the last few months. From work on the signing server and new key policy, through testing of the new update mechanism, and continuing audits of outstanding vulnerabilities. Yesterday was release day, and we also pushed security updates for 12 packages in Enterprise Linux 5.
It may seem surprising that we release security updates for a product exactly at the same time we release it, but product development is frozen for some weeks before we release the product to give time testing from the various Quality Engineering teams as well as release engineering work. During that time we want to minimise the number of changes that will invalidate the overall testing, so we instead prepare the changes as updates. Since the vulnerabilities being fixed are already public, we push the updates out as soon as we can; holding them off to some scheduled monthly date would just increase customer risk.
Security advisories for Enterprise Linux 5 are available from the usual places, on the web, sent to the enterprise-watch-list mailing list, and via OVAL definitions. Red Hat Network subscribers can also get customized mails for the subset of issues that affect the packages they actually have installed.
For me, what's going to be interesting to watch over the next few months is how specific vulnerabilities and exploits affect this platform. Red Hat Enterprise Linux 5 packages are compiled both with Fortify Source and stack smashing protection in addition to all the security features that were in version 4. I'll be reporting on what difference this makes through the year.
We're changing the package signing key we use for all new Red Hat products.
Since 1999, all RPM packages in Red Hat products have been gpg signed by the master key "Red Hat, Inc <security@redhat.com>" (keyid DB42A60E). I'll call this the legacy signing key for the rest of this article. This signature is one of two security mechanisms we use to ensure that customers can trust the installation of packages and their updates. The other is that the update client, up2date, checks the SSL server signature when it connects to the Red Hat Network to ensure that it only talks to official Red Hat servers; so removing the possibility of a man-in-the-middle attack.
From 2007, all new products will be signed with a different master key, "Red Hat, Inc. (release key) <security@redhat.com>" (keyid 37017186). This includes Red Hat Enterprise Linux 5, and any other new products that use RPM packages. The exception to this rule is that any new layered products designed for older versions of Enterprise Linux will still use the legacy key: so for example, a new version of the Application Stack for Red Hat Enterprise Linux 4 will be signed with the legacy key.
The legacy key hasn't been compromised so why change keys? It's all to do with the way the keys are stored and managed internal to Red Hat. The legacy key is a software key and so the key material exists, protected by a passphrase, on a hard disk. When packages need to be signed one of the Red Hat authorised signers manually runs a signing command, this calls rpm --resign which asks for the passphrase then in turn calls out to GNUpg to do the actual signature creation. So the authorised signers not only had the ability to sign with the key, but they also have the ability to read the key material. In theory this means that a malicious internal signer could copy the key, take it away with them, and sign whatever and whenever they
wanted. Or, more likely, a clever intruder who gained access to our internal network could perhaps capture the key and passphrase, compromising the key. The risks mean we've had to be really careful who has signing privileges with the legacy key and how the key signing is handled.
The new key, in contrast, was created in a hardware cryptographic device which does not allow the unprotected key material to be exported. This means we can give authorised signers the ability to sign with the key, but no one can ever can get access to the key material itself. This is an important distinction. If for example a current authorised signer switches roles and is no longer responsible for package signing we can instantly revoke their rights and know that they no longer have the ability to sign any more packages with that key.
There was no off-the-shelf solution available for hardware-based RPM key management, so we developed one internally ourselves. We used nCipher nShield hardware security modules (FIPS 140-2 validated) for the key protection along with custom patches I developed to interface RPM/GNUpg to the unit. At the same time we also introduced an extra layer of abstraction to the signing software, so we can authorize signers using their existing internal kerberos credentials.
So, as a customer, you won't really notice any difference. For Red Hat Enterprise Linux 5 you'll find the public keys on our website as well as in the /etc/pki/rpm-gpg/ directory and you'll be prompted when updating or installing new packages for the first time to import that new public key.
This change basically makes it easier for us to protect our signing key and reduce the risk of it being compromised, therefore reducing the chances we'll need to change the key and involve customer effort in the future.
Late last year a reporter contacted me who was interested in the various security features and innovations in Red Hat Enterprise Linux and Fedora. She particularly wanted to know the dates when each first made it into a shipping product. In the end the article was published in a German magazine and was not publically available. It's a shame to waste the work as I don't think this has ever all been collected together into one place before, so here is the table. It's possible I've missed one or two of the features, and I've not broken down the big things like SELinux where we could talk about the number of default policies in each release or the number of binaries compiled PIE, but drop me a mail if you see any issues.
| Fedora Core | Red Hat Enterprise Linux | |||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 3 | 4 | |
| 2003Nov | 2004May | 2004Nov | 2005Jun | 2006Mar | 2006Oct | 2003Oct | 2005Feb | |
| Default requires signed updates | Y | Y | Y | Y | Y | Y | Y | Y |
| NX emulation using segment limits by default | Y | Y | Y | Y | Y | Y | since 2004Sep | Y |
| Support for Position Independent Executables (PIE) | Y | Y | Y | Y | Y | Y | since 2004Sep | Y |
| ASLR for Stack/mmap by default | Y | Y | Y | Y | Y | Y | since 2004Sep | Y |
| ASLR for vDSO (if vDSO enabled) | no vDSO | Y | Y | Y | Y | Y | no vDSO | Y |
| Restricted access to kernel memory by default | Y | Y | Y | Y | Y | Y | ||
| NX by default for supported processors/kernels | since 2004Jun | Y | Y | Y | Y | since 2004Sep | Y | |
| Support for SELinux | Y | Y | Y | Y | Y | Y | ||
| SELinux default enabled with targetted policies | Y | Y | Y | Y | Y | |||
| glibc heap/memory checks by default | Y | Y | Y | Y | Y | |||
| Support for FORTIFY_SOURCE, used on selected packages | Y | Y | Y | Y | Y | |||
| All packages compiled using FORTIFY_SOURCE | Y | Y | Y | |||||
| Support for ELF Data Hardening | Y | Y | Y | Y | ||||
| All packages compiled with stack smashing protection | Y | Y | ||||||
| Pointer encryption | Y | |||||||
| CVE compatible | Y | Y | ||||||
| OVAL compatible | since 2006May | since 2006May | ||||||
New: Updated version from 7th January 2008
Red Hat Network got a minor update last night which added a couple of new security features we've been working on:
- Firstly we've added support for OVAL into Red Hat Network. This means our web site advisories contain a direct link to the relevant OVAL definition, for example https://rhn.redhat.com/rhn/oval?errata=RHSA-2006:0733
- Secondly, we've enhanced support for the severity classification which is attached to all our security advisories. In places that display lists of errata we now display the severity in a separate column, allowing them to be easily noticed and sorted.
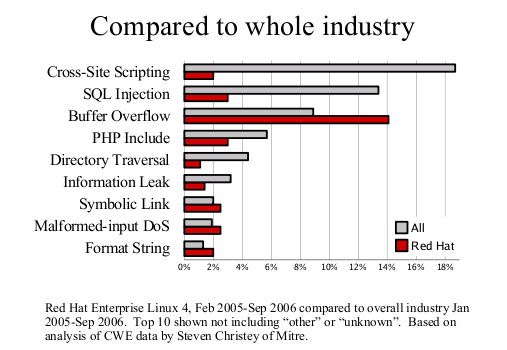
Earlier this month, Steve Christey posted a draft report of the Vulnerability Type Distributions in CVE. The report notices, amongst other things, some differences between open and closed source vendors. I thought it would be more interesting to focus just on one of our released distributions to see if it made a difference to the trends. Steve kindly provided some reports based on a list of CVE names I gave him, and this led to the analysis and these two graphs.

First, the Vulnerability Type Distribution graph. This is not really a big surprise, the most common vulnerabilities we fix are buffer overflows. Technologies such as ExecShield (PIE, support for NX, FORTIFY_SOURCE and so on) were designed specifically to reduce the risk of being able to exploit this flaw type. Secondly, compared to the industry as a whole we fix far less web application flaws such as cross-site scripting or SQL injection. This result is to be expected as most of these are in PHP web applications we don't ship in our distributions.
Our usual security audit for Fedora Core 6 is now available. For 20020101 to 20061023 there are a potential 1758 CVE named vulnerabilities that could have affected FC6 packages. 93% of those are fixed because FC6 includes an upstream version that includes a fix, 1% are still outstanding, and 6% are fixed with a backported patch. Most of those outstanding issues are for low or moderate severity flaws that are not fixed upstream.
The full details broken out by CVE name are available as at GOLD (fixed) or latest status (updated daily)
